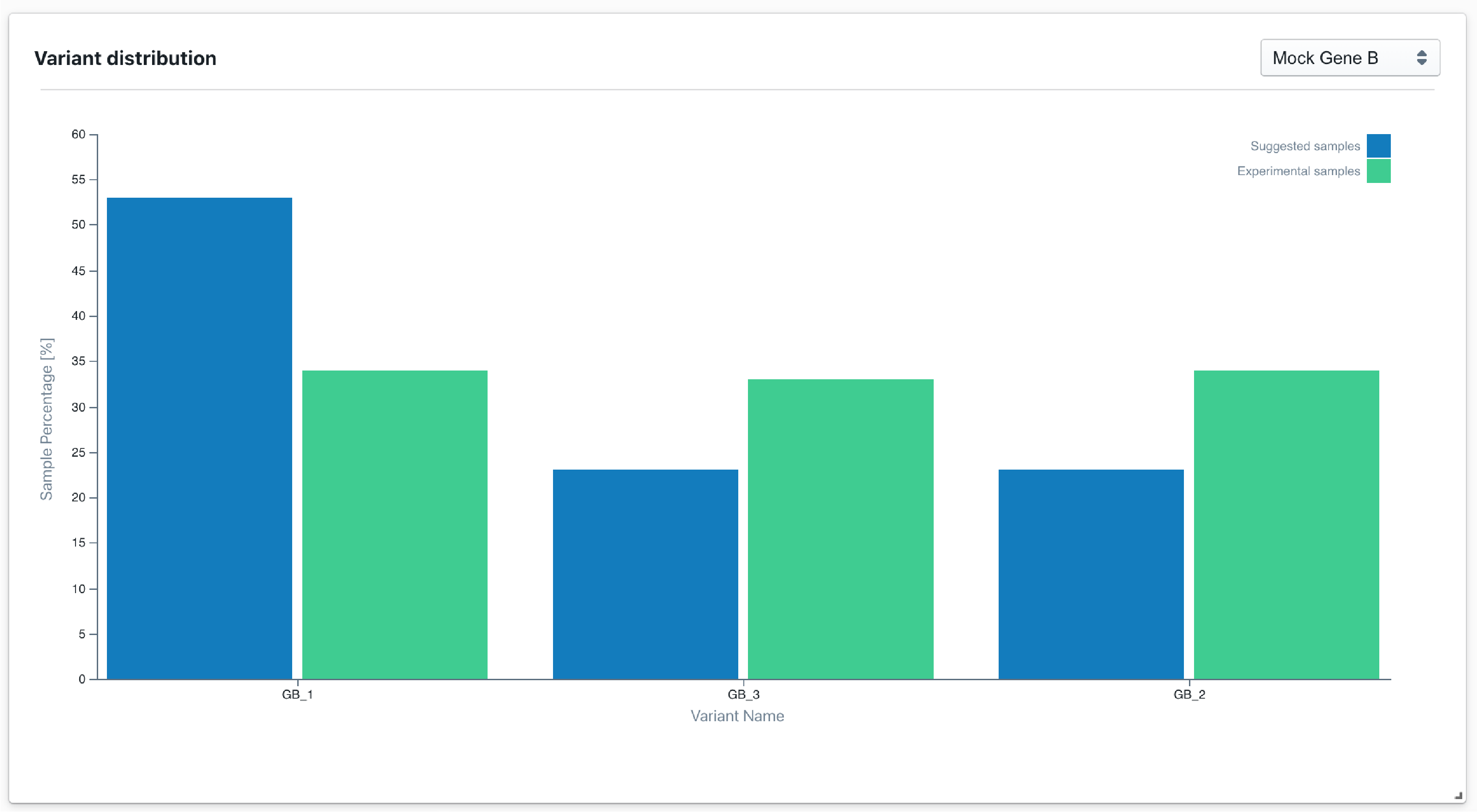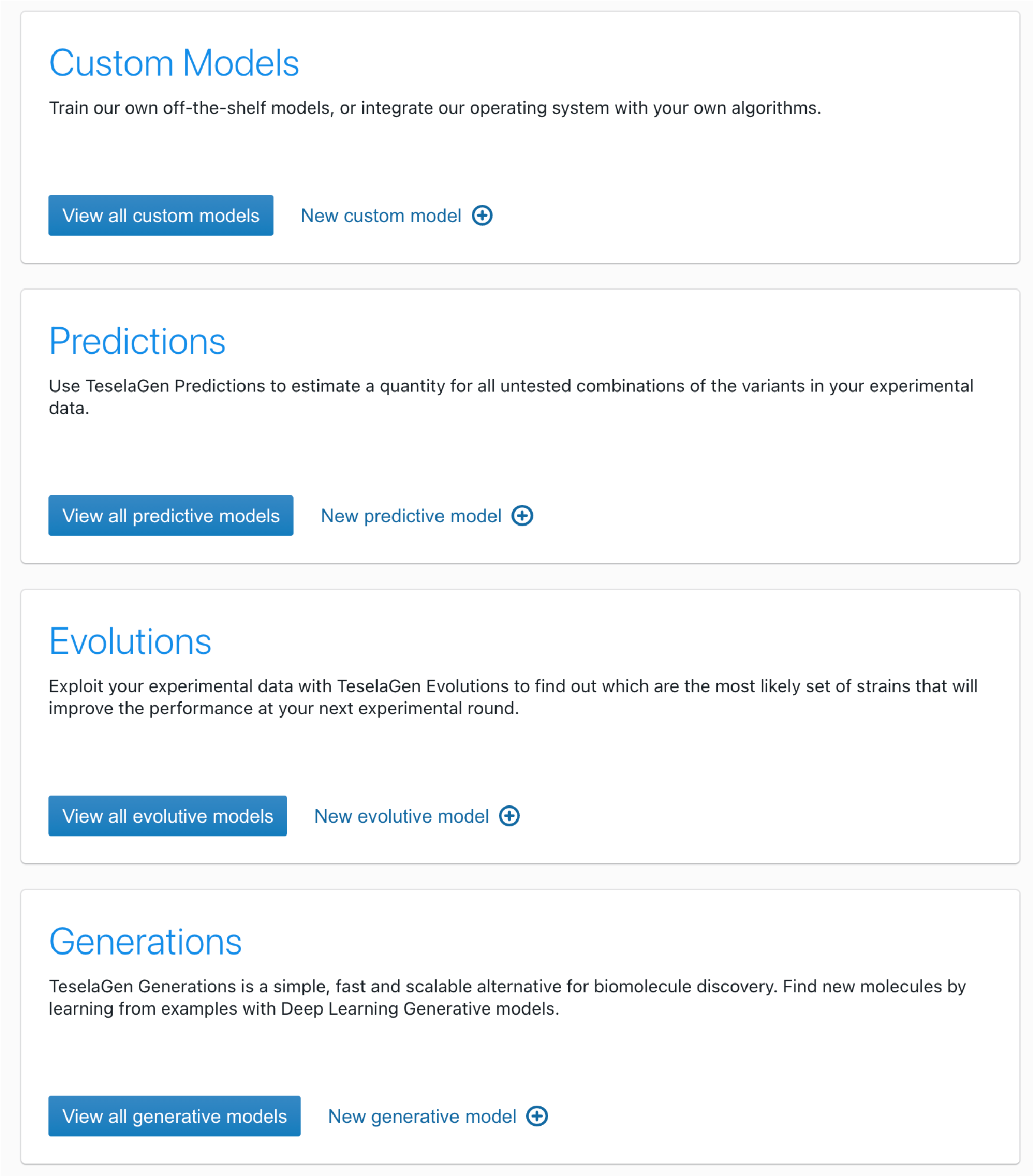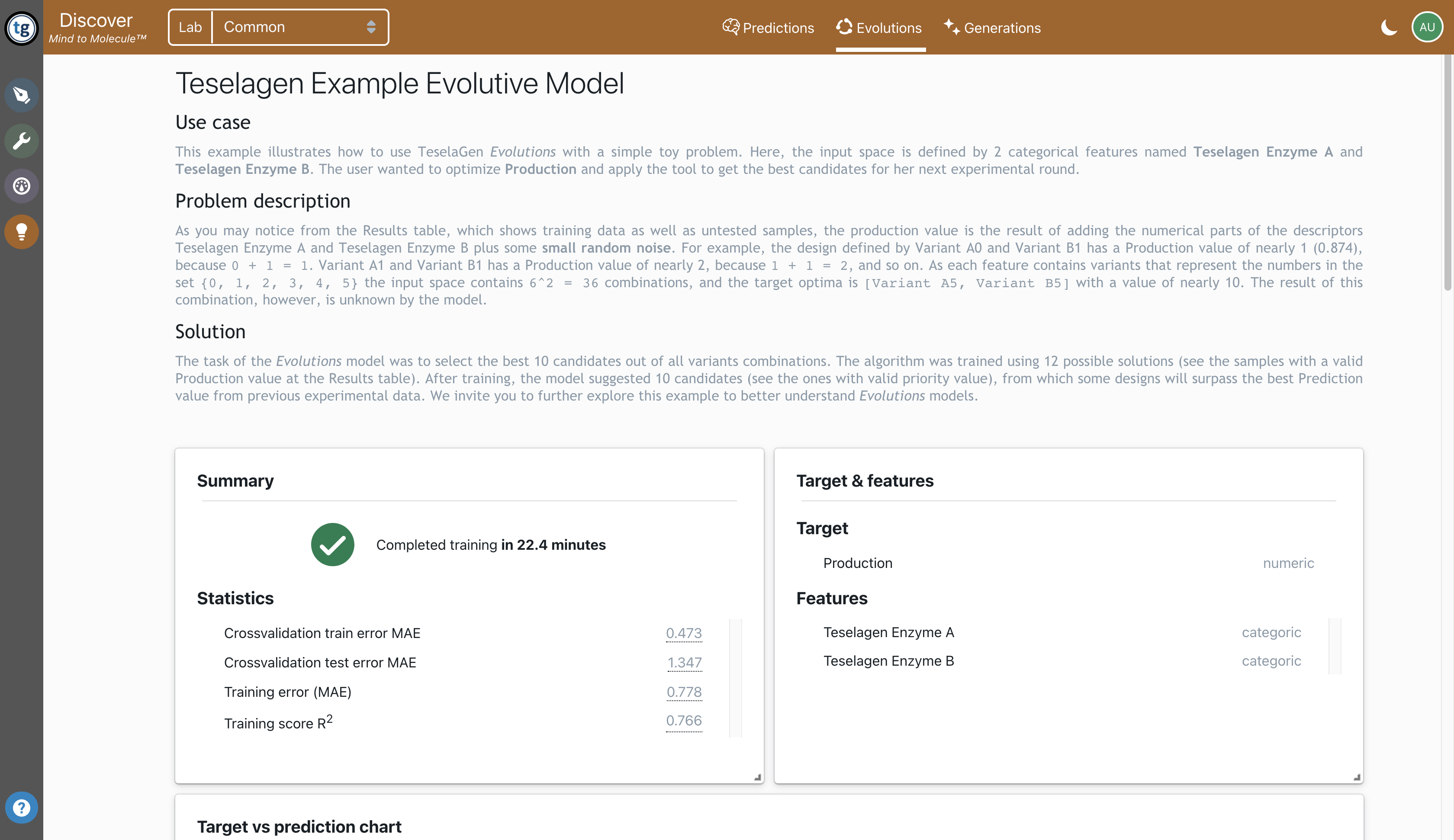
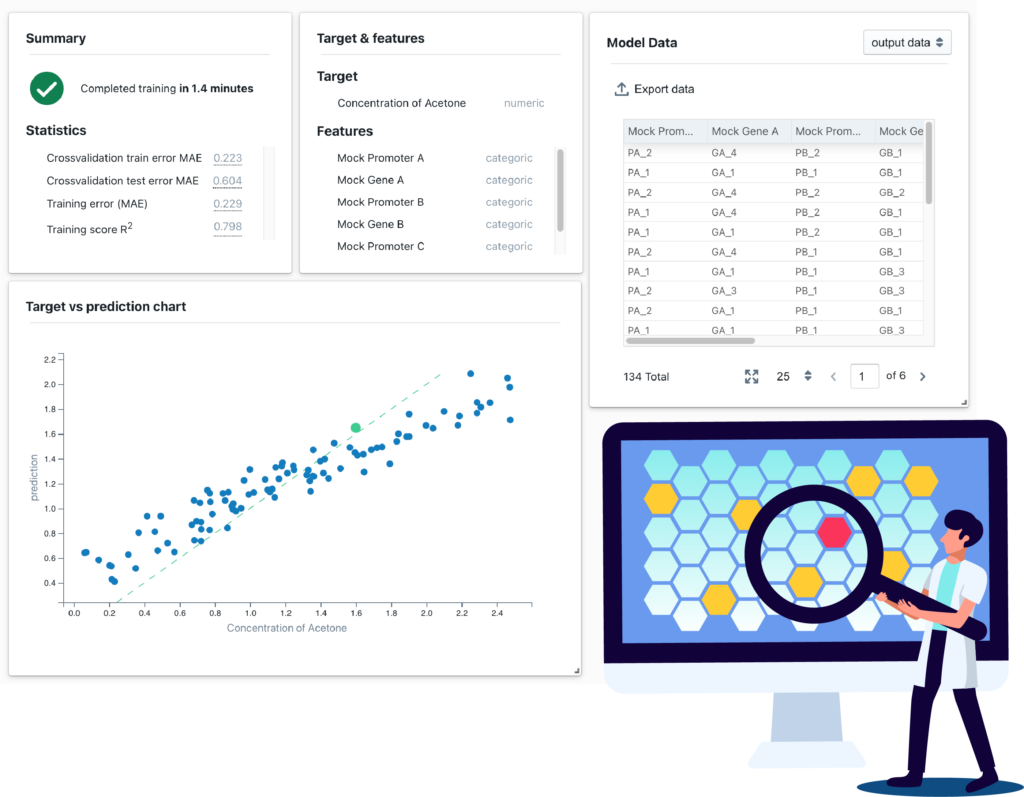
“In collaboration with TeselaGen, at DTU we have used machine learning models to generate new design recommendations, enabling us to successfully forward engineer the aromatic amino acid metabolism in yeast.”

Michael Krogh Jensen, PhD
The Novo Nordisk Foundation Center for Biosustainability